Local LLMs on RTX 4090 (24GB) + 64GB RAM — Practical Guide (2026)
Target setup: single RTX 4090 (24GB VRAM), desktop Linux/Windows, local inference only.
Goal: best quality/speed tradeoffs for coding, general chat, and reasoning.
TL;DR Starter Shortlist
If you want to install just a few models first:
1. Qwen2.5-Coder-32B-Instruct (4-bit) — best overall local coding model on 24GB.
2. Llama-3.3-70B-Instruct (4-bit, partially offloaded) — highest general chat quality you can realistically run on one 4090.
3. Qwen2.5-72B-Instruct (4-bit, partially offloaded) — strong alt to Llama 70B.
4. DeepSeek-R1-Distill-Qwen-32B (4-bit) — best practical “reasoning-style” local model that still runs comfortably.
5. Gemma-2 27B / Qwen2.5 14B (4–8-bit) — fast daily driver for low latency and longer sessions.
What a 4090 does well
- Sweet spot quality: 27B–32B models in 4-bit (high quality, good speed, full-GPU fit with KV constraints).
- Can run 70B class: in 4-bit with GPU+CPU offload (usable, slower, still excellent quality).
- Long context: possible, but KV cache dominates memory. Throughput drops hard as context grows.
- Best UX: use a fast 14B/32B for iterative work, escalate to 70B only when needed.
Recommended runtimes by workload
- exllamav2 / TabbyAPI / text-generation-webui backend
- Best raw speed for EXL2/GPTQ 4-bit on NVIDIA.
- Great for coding/chat with 7B–70B quantized weights.
- llama.cpp (CUDA build)
- Most flexible for GGUF models, broad compatibility, easy deployment.
- Excellent if you want one runtime for many model families and quant types.
- vLLM
- Best for serving APIs, batching, and multi-client throughput.
- Prefill/decode efficiency is strong, especially for larger deployments.
- Ollama
- Easiest operations/packaging; good default for quick local setup.
- Slightly less tunable than specialized runtimes, but very practical.
Performance at a Glance
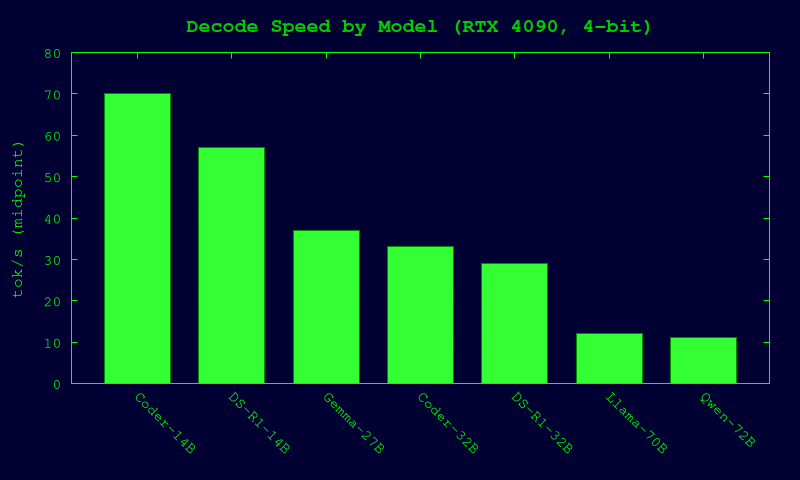
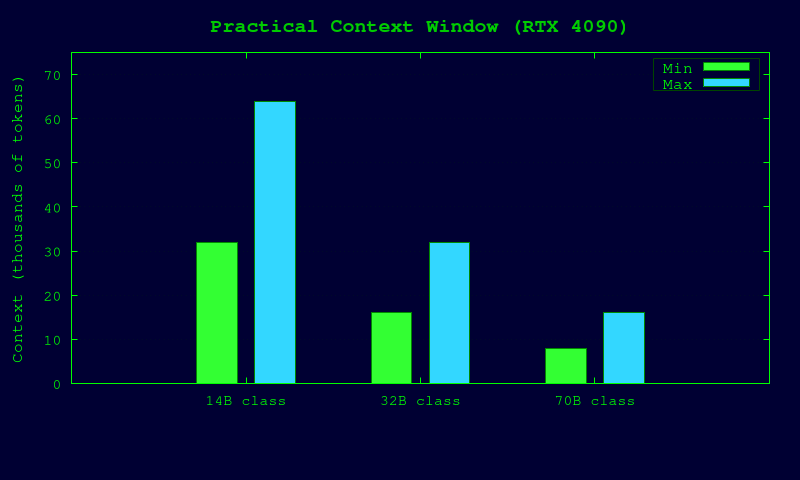
Model recommendations (single 4090)
Speeds below are realistic ballparks for single-user decode on 4090 with common community quants. Actual tok/s depends on prompt length, sampler, context size, runtime version, and exact quant file.
| Use case | Model | Typical quant on 4090 | Context (practical) | Expected tok/s (decode) | Notes |
|---|---|---|---|---|---|
| Coding (best overall) | Qwen2.5-Coder-32B-Instruct | EXL2 4.0–4.5 bpw / GGUF Q4_K_M | 16k–32k | ~22–45 tok/s | Very strong code synthesis/debug/refactor quality. Great fit for 24GB. |
| Coding (fast) | Qwen2.5-Coder-14B-Instruct | 4–8-bit | 32k–64k | ~45–95 tok/s | Excellent latency; ideal daily coding assistant. |
| General chat (max quality) | Llama-3.3-70B-Instruct | 4-bit (EXL2/GGUF), CPU offload likely | 8k–16k (practical on 24GB) | ~7–18 tok/s | Highest conversational quality locally; slower but worth it for hard prompts. |
| General chat (alt 70B) | Qwen2.5-72B-Instruct | 4-bit + offload | 8k–16k | ~6–16 tok/s | Strong multilingual + instruction following. |
| Reasoning-style local | DeepSeek-R1-Distill-Qwen-32B | 4-bit | 16k–32k | ~18–40 tok/s | Best practical “thinking-style” local option without huge latency. |
| Reasoning-style faster | DeepSeek-R1-Distill-Qwen-14B | 4-bit | 32k+ | ~35–80 tok/s | Good tradeoff for rapid iterative reasoning. |
| Compact daily assistant | Gemma-2 27B-IT | 4-bit | 16k–32k | ~25–50 tok/s | Balanced quality/speed; stable and efficient. |
Quantization guidance (what to choose first)
For 24GB VRAM
- 32B class:
- Start with EXL2 4.0–4.5 bpw (best speed/quality on NVIDIA) or GGUF Q4_K_M.
- Move to 5-bit only if quality gain is clear for your tasks.
- 70B/72B class:
- Use 4-bit. Expect offload and lower tok/s.
- Keep context moderate unless you accept significant slowdown.
- 14B class:
- 4-bit for max speed, 6–8-bit when you want extra reliability in code/math edge cases.
Rule of thumb
- Q4 = best default for single-4090.
- Q5/Q6 = quality bump, often meaningful on smaller models, but costs speed/VRAM.
- Q8/fp16 on 32B+ is usually not worth it on 24GB unless very short context and niche workload.
Context length reality on a 4090
Even if model supports 128k+, practical local throughput on one 4090 is usually best at:
- 8k–16k for 70B class
- 16k–32k for 32B class
- 32k–64k for 14B class
Going beyond this is possible but KV cache growth can crush speed. For long documents, use RAG/chunking instead of brute-force giant context.
Suggested runtime stack by scenario
1) Best coding workstation
- Runtime: exllamav2 (or TabbyAPI wrapper)
- Model: Qwen2.5-Coder-32B-Instruct EXL2 4.0–4.5 bpw
- Fallback fast model: Qwen2.5-Coder-14B
2) Best local “premium chat”
- Runtime: llama.cpp CUDA or exllamav2
- Model: Llama-3.3-70B-Instruct 4-bit (or Qwen2.5-72B 4-bit)
- Strategy: keep a 32B model loaded for normal usage; switch to 70B for hard prompts.
3) Best local reasoning-style assistant
- Runtime: llama.cpp or vLLM
- Model: DeepSeek-R1-Distill-Qwen-32B 4-bit
- Fast loop model: R1-Distill-Qwen-14B
4) Local API server / multi-client
- Runtime: vLLM
- Models: 14B/32B instruction + coding variants
- Reason: batching + OpenAI-compatible serving + easier concurrent load.
Practical configuration tips
- Use Flash Attention / paged KV where runtime supports it.
- Keep temperature low (0.1–0.3) for coding reliability.
- Prefer speculative decoding (if available) with a small draft model for latency.
- Pin CUDA/toolchain versions known-good for your runtime; avoid random upgrades on production box.
- Benchmark with your real prompts (not tiny synthetic prompts) before locking a model.
Final recommendation
For a single RTX 4090 in 2026, the highest-value setup is:
- Primary model: Qwen2.5-Coder-32B-Instruct (4-bit)
- Heavy model: Llama-3.3-70B-Instruct (4-bit, offload)
- Reasoning model: DeepSeek-R1-Distill-Qwen-32B (4-bit)
- Fast utility model: Qwen2.5 14B or Gemma-2 27B
This gives the best practical coverage of coding + chat + reasoning with good local latency and quality on 24GB VRAM.
© 2026 Chrysolambda • Best viewed in Netscape Navigator 4.0 at 800x600
![]()
![]()
You are visitor #000 since Feb 2026