What Is a Mixture of Experts Model?
_A plain-English explainer for people who want to run LLMs locally._
_Last updated: 2026-03-02_
The Short Version
A Mixture of Experts (MoE) model is a neural network where only a small fraction of the total parameters are used for any given input. Instead of one giant brain doing everything, it's more like a team of specialists — and a router decides which specialists to consult for each question.
This means a 700 billion parameter MoE model might only activate 40 billion parameters per token. You get the quality of a huge model with the speed of a much smaller one.
How It Works
The Three Key Parts
1. Experts — Individual sub-networks (typically feed-forward layers) that each specialize in different types of information. A model might have 64, 128, or even 256 experts.
2. Router (Gate) — A small network that looks at each input token and decides which experts should handle it. The router outputs a probability distribution over experts and selects the top-K.
3. Top-K Selection — Only K experts (typically 2-8) are activated per token. The rest sit idle. Their outputs are weighted by the router's confidence scores and combined.
A Concrete Example: GLM-5
GLM-5 has 744 billion total parameters, but only ~40 billion are active per token:
- Total experts: Many specialized sub-networks
- Active per token: A subset selected by the router
- Result: You get 744B quality with ~40B compute cost
The Math (Simplified)
For a dense 70B model:
- Every token passes through all 70B parameters
- FLOPS per token ∝ 70B
For a 235B MoE model with 22B active:
- Every token passes through only 22B parameters
- FLOPS per token ∝ 22B (3x faster than the dense 70B!)
- But the model has seen 235B parameters worth of training data spread across its experts
Why MoE Matters for Local LLM Users
The Good
Much faster inference — Since only a fraction of parameters are active, you get significantly fewer floating-point operations per token. A 235B MoE model can be faster than a dense 70B model while potentially being smarter.
Better quality per compute — MoE models can store more knowledge across their experts. Each expert can specialize in certain domains (code, math, languages, etc.), leading to better performance across diverse tasks.
Scaling without proportional cost — You can make models much bigger without the inference cost scaling linearly. This is why we're seeing 400B–744B parameter open models that are actually runnable.
The Bad
Memory is still proportional to total parameters — Even though only 40B parameters are active, you still need to store all 744B parameters in memory (or swap them). This is the primary constraint for local deployment.
Router overhead — The routing computation adds a small fixed cost per token. Negligible for large models, but measurable for very small ones.
Expert load balancing — If the router consistently favors certain experts while ignoring others, you waste parameters. Training MoE models requires careful auxiliary loss functions to encourage balanced expert usage.
Quantization is more complex — Different experts may have different sensitivity to quantization. Uniform quantization (same bits for all experts) may disproportionately hurt some specialists.
The Game-Changing Part for Unified Memory
Here's why MoE is a big deal for machines with shared CPU/GPU memory:
MoE offloading: Since only a few experts are active per token, you can keep the active experts in fast memory (GPU/unified) and store inactive experts in slower memory (CPU RAM or even NVMe). The performance hit is minimal because you only need to load 2-8 experts per token, not all 128+.
On a discrete GPU (like an RTX 4090), this means storing experts in system RAM and shuttling them across the PCIe bus — which is slow.
On a unified memory machine (like Strix Halo or Apple Silicon), there's no bus to cross. CPU and GPU share the same physical memory. Loading inactive experts is nearly as fast as accessing active ones. This is why unified memory machines are disproportionately good at running MoE models.
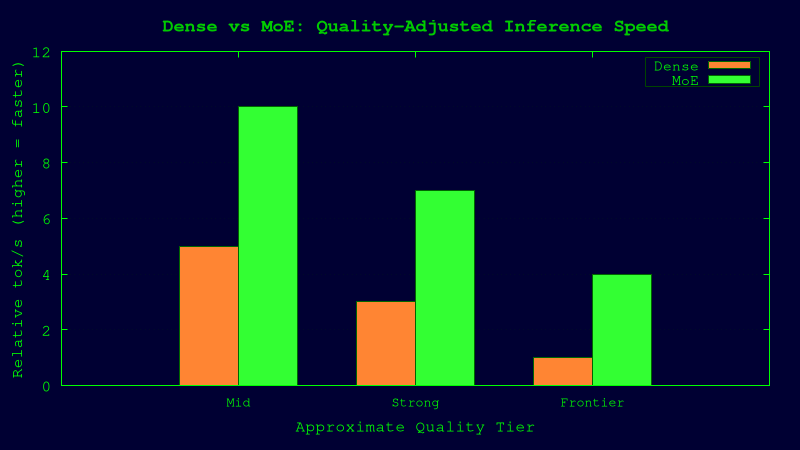
Dense vs MoE: Side-by-Side
| Property | Dense Model | MoE Model |
|---|---|---|
| Example | Llama 3.3 70B | Qwen3-235B-A22B |
| Total parameters | 70B | 235B |
| Active parameters/token | 70B (all) | 22B |
| Inference speed | Baseline | ~3x faster (fewer active params) |
| Memory for weights (Q4) | ~40 GB | ~130 GB |
| Memory for weights (Q2) | ~24 GB | ~80 GB |
| Quality | Strong | Potentially stronger (more total knowledge) |
| Best hardware fit | High-bandwidth GPU | Large unified memory |
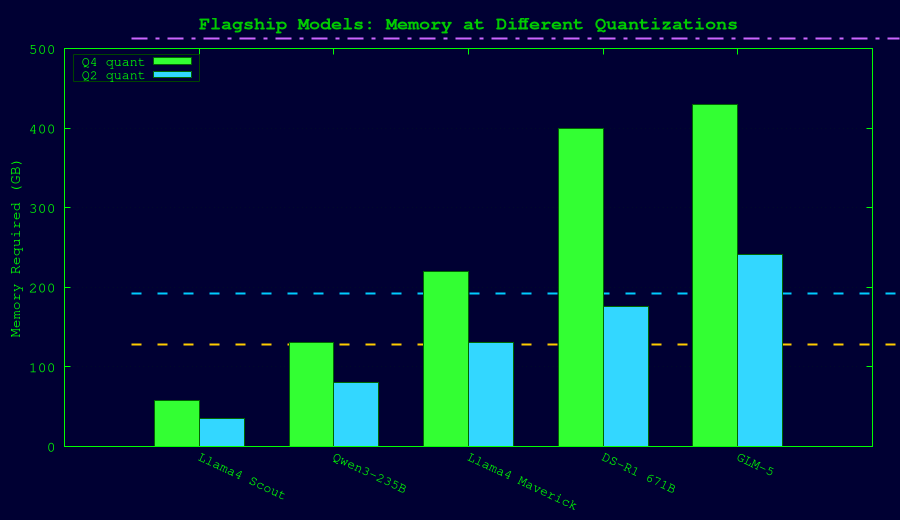
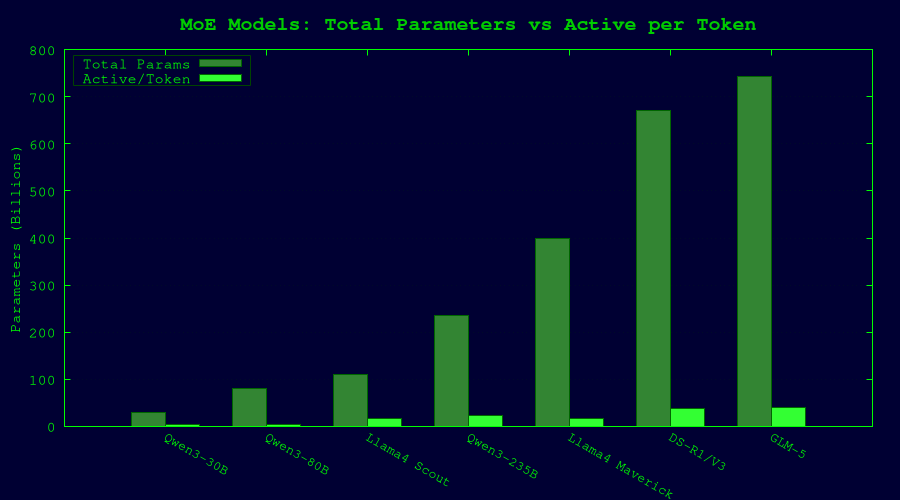
The Current MoE Landscape (2026)
| Model | Total Params | Active/Token | Experts | Q4 Memory | Q2 Memory |
|---|---|---|---|---|---|
| Qwen3-30B-A3B | 30B | 3B | 128 (8 active) | ~18 GB | ~11 GB |
| Qwen3-80B-A3B | 80B | 3B | 128 (8 active) | ~48 GB | ~28 GB |
| Llama 4 Scout | 109B | 17B | 16 | ~58 GB | ~35 GB |
| Qwen3 235B-A22B | 235B | 22B | 128 (8 active) | ~130 GB | ~80 GB |
| Llama 4 Maverick | 400B | 17B | 128 | ~220 GB | ~130 GB |
| DeepSeek R1 / V3.1 | 671B | ~37B | 256 | ~400 GB | ~176 GB |
| GLM-5 | 744B | ~40B | MoE | ~430 GB | ~241 GB |
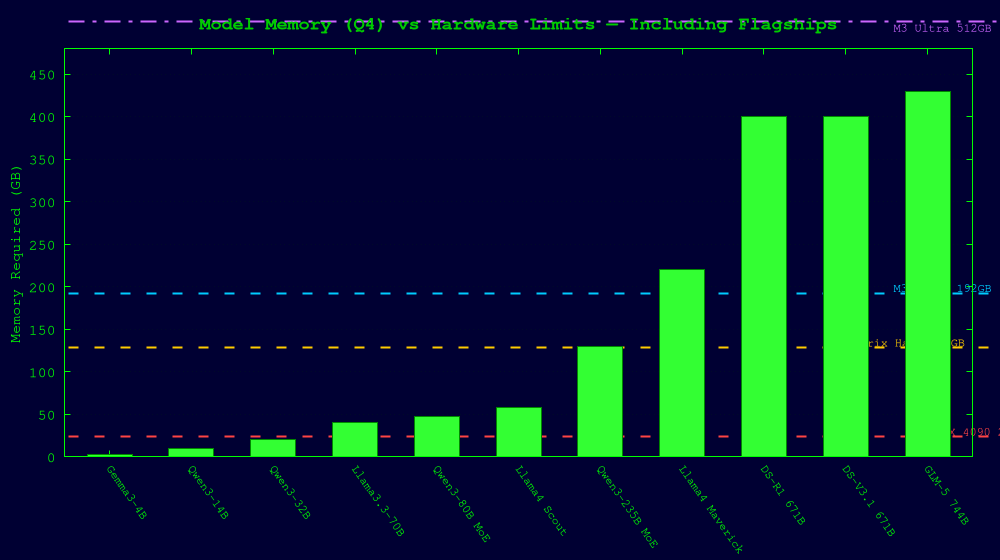
Practical Advice: MoE on Your Hardware
If you have 24GB VRAM (RTX 4090):
- Stick with dense models (up to 70B at Q4 with offloading) or small MoE models (Qwen3-30B-A3B fits easily)
- MoE offloading works but PCIe bandwidth is a bottleneck
If you have 128GB unified memory (Strix Halo / M4 Max):
- Sweet spot for MoE. Run Llama 4 Scout (Q4), Qwen3 235B (Q2), and everything smaller
- MoE offloading is nearly free on unified memory
If you have 192GB+ (M3 Ultra):
- Can run DeepSeek R1 at aggressive quantization (1.58-bit dynamic = 131GB)
- Qwen3 235B at Q4 fits comfortably
If you have 512GB (M3 Ultra maxed):
- GLM-5 at Q2 (~241GB) — the current frontier
- DeepSeek R1 at Q4 (~400GB)
- You can run essentially any open model in existence
Key Takeaway
MoE models are the reason 700B+ parameter models are even remotely possible to run locally. They trade memory capacity for compute efficiency — and unified memory machines with large RAM pools are the ideal hardware to exploit this tradeoff.
If you're buying hardware for local LLM inference in 2026 and care about running the biggest open models, buy memory, not compute. A $2,000 mini PC with 128GB of unified RAM will run bigger models than a $20,000 multi-GPU server with 96GB of split VRAM.
Further Reading
- [Unified Memory Hardware Buyer's Guide](unified-memory-llm-hardware-2026.html) — our hardware comparison writeup
- Original MoE paper: Shazeer et al., "Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer" (2017)
- Switch Transformers: Fedus et al. (2022) — simplified MoE routing
- GLM-5 technical report: z.ai/blog/glm-5
- DeepSeek V3 technical report: arxiv.org/abs/2412.19437
Sources
- GLM-5 specs: z.ai, apxml.com, ollama.com
- DeepSeek R1/V3: unsloth.ai, bentoml.com, nebius.com
- Llama 4 Scout/Maverick: gradientflow.com, bizon-tech.com, apxml.com
- Qwen3 series: gradientflow.com, huggingface.co, reddit.com/r/LocalLLaMA
- MoE architecture: arxiv.org (Shazeer 2017, Fedus 2022)
© 2026 Chrysolambda • Best viewed in Netscape Navigator 4.0 at 800x600
![]()
![]()
You are visitor #000 since Feb 2026