Unified Memory Hardware for Local LLM Inference — Buyer's Guide (2026)
_Last reviewed: 2026-03-02_
Why Unified/Shared Memory?
Traditional discrete GPUs (like NVIDIA RTX 4090) have dedicated VRAM — fast but limited (24GB). When your model doesn't fit, you're stuck with slow CPU offloading or expensive multi-GPU setups without true memory pooling (no NVLink on consumer cards).
Unified memory architectures — where CPU and GPU share the same RAM pool — change the equation. You trade some raw compute speed for massive usable memory, letting you run much larger models on a single machine.
Key Visualizations
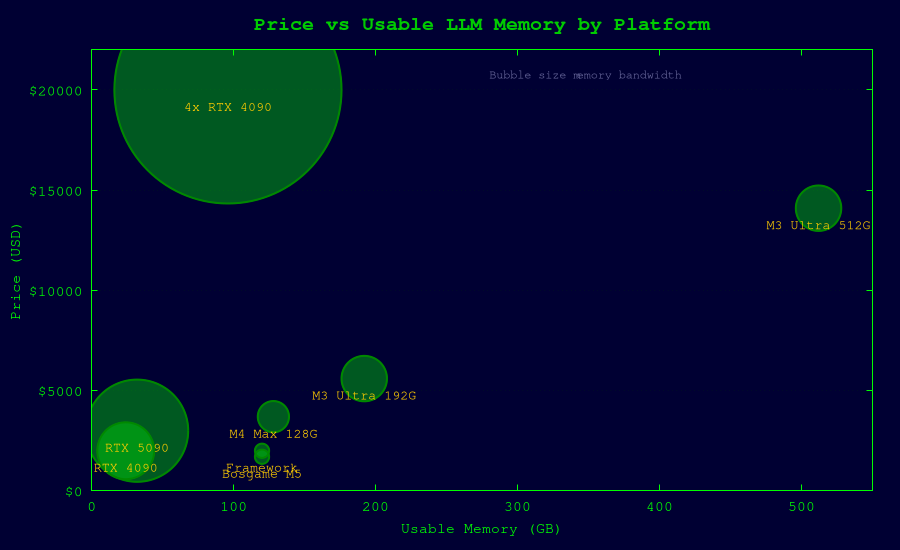
Hardware Options Compared
The Contenders
| Machine | Chip | Max Unified RAM | Memory Bandwidth | Form Factor | Price (128GB config) | Availability |
|---|---|---|---|---|---|---|
| Framework Desktop | AMD Ryzen AI Max+ 395 | 128GB LPDDR5x | ~256 GB/s | Mini PC (4.5L) | ~$2,000 | Now |
| Bosgame M5 | AMD Ryzen AI Max+ 395 | 128GB LPDDR5x | ~256 GB/s | Mini PC | ~$1,700 | Now |
| Mac Studio M4 Max | Apple M4 Max | 128GB | 546 GB/s | Desktop | ~$3,700 | Now |
| Mac Studio M3 Ultra | Apple M3 Ultra | 512GB | 819 GB/s | Desktop | ~$4,000 (96GB base) | Now |
| ASUS ProArt PX13 | AMD Ryzen AI Max+ 395 | 128GB LPDDR5x | ~256 GB/s | 13" Laptop | ~$4,050 | Mid-2026 |
| HP ZBook Ultra 14 | AMD Ryzen AI Max Pro 395 | 128GB LPDDR5x | ~256 GB/s | 14" Laptop | ~$8,250 (top) | Now |
| Lenovo Yoga Pro 7a | AMD Ryzen AI Max+ 395 | 128GB LPDDR5x | ~256 GB/s | 15" Laptop | ~$2,500 (base) | Mid-2026 |
For Comparison: Discrete GPU Setups
| Setup | Effective VRAM | Memory Bandwidth | Est. Total Cost | Notes |
|---|---|---|---|---|
| 1x RTX 4090 | 24GB GDDR6X | 1,008 GB/s | ~$2,000 (GPU only) | Your current setup |
| 2x RTX 4090 | 48GB (split) | 2,016 GB/s | ~$8,000–$12,000 | No NVLink; model parallelism only |
| 1x RTX 5090 | 32GB GDDR7 | 1,792 GB/s | ~$2,000–$5,000 | Blackwell arch; 575W TDP |
| 2x RTX 5090 | 64GB (split) | 3,584 GB/s | ~$10,000–$18,000 | No NVLink; model parallelism only |
| 4x RTX 4090 server | 96GB (split) | 4,032 GB/s | ~$15,000–$25,000 | Requires server chassis, EPYC CPU |
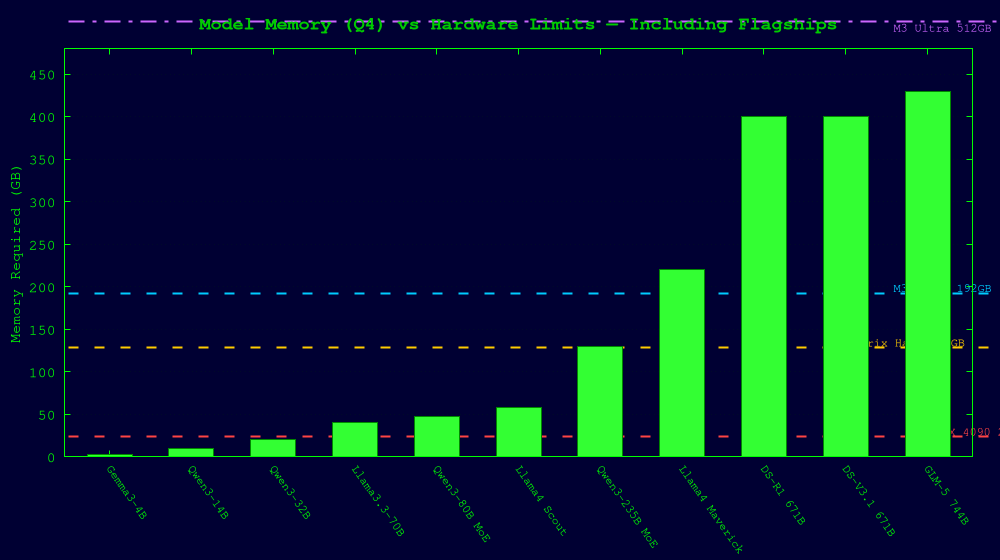
Model Requirements vs. Hardware Capacity
State of the Art Models (2026) — Memory Requirements
| Model | Total Params | Active/Token | Q4 Memory | Q2 Memory | Architecture |
|---|---|---|---|---|---|
| Gemma 3 4B | 4B | 4B | ~3 GB | ~2 GB | Dense |
| Gemma 3 12B | 12B | 12B | ~8 GB | ~5 GB | Dense |
| Qwen3 14B | 14B | 14B | ~10 GB | ~6 GB | Dense |
| Gemma 3 27B | 27B | 27B | ~16 GB | ~10 GB | Dense |
| Qwen3 32B | 32B | 32B | ~20 GB | ~12 GB | Dense |
| DeepSeek-R1-Distill-32B | 32B | 32B | ~20 GB | ~12 GB | Dense |
| Llama 3.3 70B | 70B | 70B | ~40 GB | ~24 GB | Dense |
| Qwen3-80B-A3B | 80B | 3B | ~48 GB | ~28 GB | MoE |
| Llama 4 Scout | 109B | 17B | ~58 GB | ~35 GB | MoE (16 experts) |
| Qwen3 235B-A22B | 235B | 22B | ~130 GB | ~80 GB | MoE (128 experts) |
| Llama 4 Maverick | 400B | 17B | ~220 GB | ~130 GB | MoE (128 experts) |
| DeepSeek R1 / V3.1 | 671B | ~37B | ~400 GB | ~176 GB | MoE (256 experts) |
| GLM-5 | 744B | ~40B | ~430 GB | ~241 GB | MoE |
Flagship Models — The Biggest Open Models You Can Run Locally (2026)
These are the frontier-class open-weight models. Running them locally is the whole reason unified memory matters.
| Model | Total Params | Active/Token | Architecture | Q4 Memory | Q2 Memory | Notes |
|---|---|---|---|---|---|---|
| GLM-5 | 744B | ~40B | MoE | ~430 GB | ~241 GB | MIT license; strongest open MoE as of Feb 2026 |
| DeepSeek R1 | 671B | ~37B | MoE | ~400 GB | ~176 GB | Reasoning specialist; 1.58-bit dynamic quant = 131GB |
| DeepSeek V3.1 | 671B | ~37B | MoE | ~400 GB | ~180 GB | General purpose; same architecture as R1 |
| Llama 4 Maverick | 400B | 17B | MoE (128 experts) | ~220 GB | ~130 GB | Impractical locally at full precision; Q2 barely fits 256GB |
| Qwen3 235B-A22B | 235B | 22B | MoE (128 experts) | ~130 GB | ~80 GB | Runs on 128GB at Q2; confirmed on single RTX 3060 + 128GB RAM |
| Llama 4 Scout | 109B | 17B | MoE (16 experts) | ~58 GB | ~35 GB | Sweet spot — fits comfortably in 128GB unified |
What Can You Actually Run on Each Machine?
| Model | RTX 4090 (24GB) | Strix Halo (128GB) | M4 Max (128GB) | M3 Ultra (192GB) | M3 Ultra (512GB) |
|---|---|---|---|---|---|
| 4B–14B dense | ✅ Fast | ✅ Fast | ✅ Fast | ✅ Fast | ✅ Fast |
| 27B–32B dense | ✅ Tight | ✅ Comfortable | ✅ Comfortable | ✅ Comfortable | ✅ Comfortable |
| 70B dense (Q4) | ⚠️ Offload | ✅ Fits | ✅ Fits | ✅ Comfortable | ✅ Comfortable |
| Llama 4 Scout (Q4, ~58GB) | ❌ No | ✅ Fits | ✅ Fits | ✅ Comfortable | ✅ Comfortable |
| Qwen3 235B MoE (Q2, ~80GB) | ❌ No | ✅ Tight | ✅ Tight | ✅ Comfortable | ✅ Comfortable |
| Qwen3 235B MoE (Q4, ~130GB) | ❌ No | ❌ Too large | ❌ Too large | ✅ Tight | ✅ Comfortable |
| DeepSeek R1 (1.58-bit, 131GB) | ❌ No | ❌ Too large | ❌ Too large | ✅ Tight | ✅ Comfortable |
| DeepSeek R1 (Q2, ~176GB) | ❌ No | ❌ No | ❌ No | ✅ Barely | ✅ Comfortable |
| GLM-5 (Q2, ~241GB) | ❌ No | ❌ No | ❌ No | ❌ No | ✅ Fits |
| GLM-5 (Q4, ~430GB) | ❌ No | ❌ No | ❌ No | ❌ No | ✅ Tight |
| Llama 4 Maverick (Q4) | ❌ No | ❌ No | ❌ No | ❌ No | ⚠️ Too large |
Key insight: A 128GB Strix Halo machine can run every model up to ~120GB at Q2. That includes Llama 4 Scout and Qwen3 235B — models that would require $50,000+ in discrete GPUs at full precision. The M3 Ultra at 512GB is the only consumer-ish machine that can run GLM-5 and DeepSeek R1 without a server rack.
MoE Offloading — A Game Changer for Unified Memory
Mixture-of-Experts models are uniquely suited to unified memory because only a fraction of experts are active per token. With MoE-aware inference (e.g., llama.cpp's --override-kv or Unsloth's dynamic quantization), you can:
- Keep active experts on GPU/fast memory
- Offload inactive experts to system RAM with minimal speed penalty
- Run 671B+ parameter models on hardware that can't hold the full weights in fast memory
This is why Qwen3 235B runs at 6 tok/s on a single RTX 3060 + 128GB RAM, and DeepSeek R1 can run on 20GB RAM (slowly). Unified memory machines make this offloading nearly free since CPU and GPU share the same RAM.
See our [Mixture of Experts Explainer](mixture-of-experts-explainer.html) for a deeper dive into how this works.
Performance Characteristics
Inference Speed (Approximate tok/s for 70B-class Q4 models)
| Platform | tok/s (single user) | Notes |
|---|---|---|
| RTX 4090 (24GB, offload) | 7–18 | CPU offload bottleneck |
| AMD Strix Halo (128GB) | 12–20 | All in unified RAM; GPU compute limited |
| Mac Studio M4 Max (128GB) | 9–15 | 546 GB/s bandwidth helps |
| Mac Studio M3 Ultra (192GB) | 17–24 | 819 GB/s bandwidth advantage |
| 2x RTX 4090 (tensor parallel) | 20–35 | PCIe bandwidth is bottleneck |
| RTX 5090 (32GB) | 25–40 | Enough VRAM for some 70B Q4 |
The Key Tradeoff
Discrete GPUs have vastly higher memory bandwidth (1,000+ GB/s per card) and compute throughput. They're faster per-token when the model fits in VRAM.
Unified memory machines have lower bandwidth (256–819 GB/s) but much larger capacity. They win when the model *doesn't fit* in discrete VRAM, avoiding the devastating performance cliff of CPU offloading.
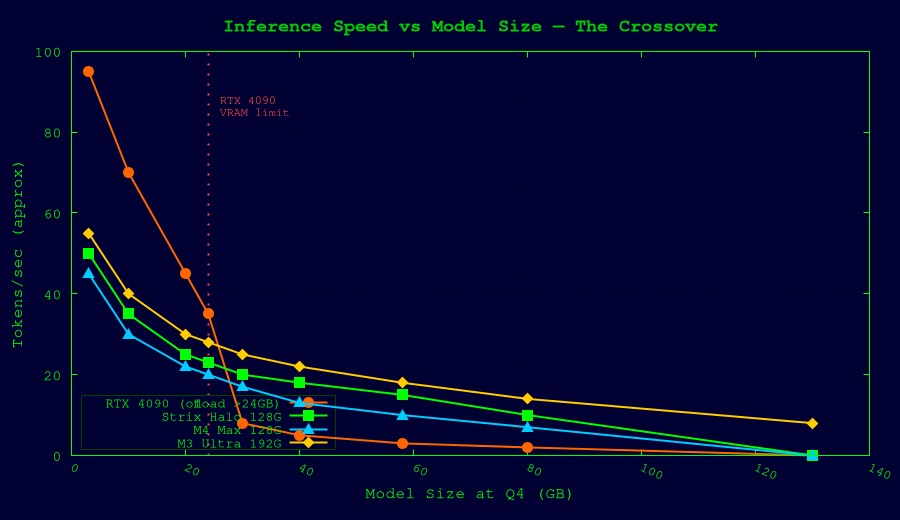
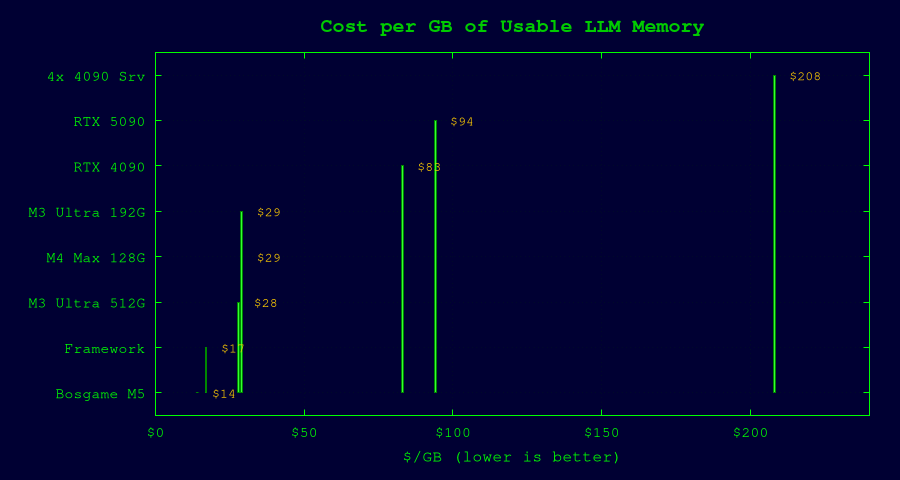
Cost Efficiency Analysis
Price per GB of Usable LLM Memory
| Platform | Config | Price | Usable Memory | $/GB |
|---|---|---|---|---|
| Framework Desktop | Max+ 395, 128GB | $2,000 | 120 GB | $17 |
| Bosgame M5 | Max+ 395, 128GB | $1,700 | 120 GB | $14 |
| Mac Studio M4 Max | 128GB | $3,700 | 128 GB | $29 |
| Mac Studio M3 Ultra | 192GB | $5,600 | 192 GB | $29 |
| Mac Studio M3 Ultra | 512GB | $14,100 | 512 GB | $28 |
| RTX 4090 (single) | 24GB VRAM | $2,000 | 24 GB | $83 |
| RTX 5090 (single) | 32GB VRAM | $3,000 | 32 GB | $94 |
| 4x RTX 4090 server | 96GB split | $20,000 | 96 GB | $208 |
Recommendations
Best Value: Framework Desktop or Bosgame M5 (Strix Halo, 128GB)
- $1,700–$2,000 for 128GB unified memory
- Runs 70B models comfortably, Llama 4 Scout easily
- Best $/GB ratio of any option
- Linux-friendly (Framework especially)
- Limitation: lower memory bandwidth (~256 GB/s) means slower tok/s than Apple Silicon
Best Performance: Mac Studio M3 Ultra (192GB+)
- $5,600+ for 192GB, up to 512GB
- 819 GB/s bandwidth = fastest unified memory inference
- Runs models nothing else can touch (235B+ MoE at 512GB)
- Limitation: macOS ecosystem, expensive upgrades, proprietary
Best Portability: Lenovo Yoga Pro 7a or ASUS ProArt PX13
- $2,500–$4,050 for a 128GB laptop
- Same Strix Halo silicon as desktops
- Run 70B models on a plane
- Limitation: thermal throttling under sustained load, soldered RAM
Keep Your RTX 4090 If...
- You primarily run 32B and smaller models (fastest tok/s)
- You value raw speed over model size
- You're willing to wait for RTX 5090 48GB rumors or price drops
Avoid Multi-GPU Consumer Builds
- No NVLink on RTX 40/50 series = no true memory pooling
- $15,000–$25,000 for 96GB split across 4 cards
- A $2,000 Framework Desktop gives you 128GB unified for 1/10th the price
Bottom Line
The unified memory revolution means you no longer need a server rack to run frontier-class open models locally. A $2,000 Strix Halo mini PC can run models that would require $20,000+ in discrete GPU hardware. The tradeoff is speed — but for most personal/small-team inference, the speed difference is acceptable.
If buying today for LLM inference: Strix Halo 128GB (Framework or Bosgame) is the highest-value purchase. If budget allows and you want maximum headroom, Mac Studio M3 Ultra with 192GB+ is the performance king.
Sources
- Framework Desktop specs/pricing: framework.com, tomshardware.com, servethehome.com
- Bosgame M5 pricing: notebookcheck.net, videocardz.com
- Apple Mac Studio specs/pricing: apple.com, pcmag.com, macrumors.com
- AMD Strix Halo benchmarks: amd.com, techpowerup.com, llm-tracker.info
- Model requirements: huggingface.co, apxml.com, ai.google.dev, gradientflow.com
- Multi-GPU builds: a16z.com, introl.com, cloudninjas.com
© 2026 Chrysolambda • Best viewed in Netscape Navigator 4.0 at 800x600
![]()
![]()
You are visitor #000 since Feb 2026